This is part two of a three-part series. This is a comprehensive guide to a basic development workflow. Using a simple, but non-trivial web application, we learn how to write tests, fix bugs, and add features using pytest and git, via feature branches. Along the way we'll touch on application design and discuss best practices.
In this installment, we will:
- Identify and fix a bug on a branch.
- Build a new feature, also on a branch.
- Use
git rebaseto keep our change history tidy. - Use tagging to mark new versions of our application.
Setup
Make sure you've got everything set up as outlined in part 1.
Here's a condensed summary:
Ensure you have git, python 3.7+, and venv installed.
Make a bare clone of the base repository to act as our remote:
$ git clone --bare https://github.com/jjmojojjmojo/random_quote.git random_quote_remote
Clone our remote:
$ git clone random_quote_remote random_quote
Initialize the virtual environment, and install our requirements and project:
$ cd random_quote $ python -m venv . $ source bin/activate (random_quote) $ pip install -r requirements.txt (random_quote) $ pip install -e .
Initialize the database, add some randomly generated quotes:
(random_quote) $ python scripts/generate_quotes.py (random_quote) $ python >>> from random_quote import util >>> util.init("test.db") util.ingest("quotes.csv", "test.db")
Add the
fix_random()test fixture and the extra tests for random functionality. If you had trouble, or would like to skipscripts/state/part1, you cangit checkoutthepart1branch:(random_quote) $ git checkout part1Tip
🌈 We have branches for all of the major work done in the series:
part1All the changes from part 1.
part2qotdDeveloper A's feature from part 3.
index-infoDeveloper B's bug fix from part 3.
part3
Feel free to
git checkoutif you need to reset your code, or jump around.Use
git stashto keep any uncommitted changes for later. See the git documentation for more information. 🦄
Let's Find A Bug!
Let's run the application locally so we can play with it in a browser, and identify a bug to fix.
requirements.txt has installed a web server for us called Gunicorn. It's a pure-python server that has a lot of great production-quality features.
We'll start the gunicorn server using a couple of useful command-line options, since we'll be messing with the code:
(random_quote) $ gunicorn -b 127.0.0.1:8080 -t 9999999 -w 1 --reload wsgi:app
Explanation
Gunicorn is a multi-process server. This means it spawns multiple python processes and hands off web requests to them as needed, usually in a round-robin fashion. The processes are killed if they run for too long.
The first option, -b sets the bind port - it's an IP address followed by a port number. Numbers under 1024 are available to you without running with elevated privileges (aka "as root"). The default port is 8000. You can omit this parameter if you'd like, but it's really useful when you're running a bunch of stuff, or for deployment, so it's good practice to get used to using it.
Next option, -t sets the the timeout before a worker is killed and reclaimed. We set this to a very long time so if we are doing something like running a pdb session, it won't kick us out before we're done.
The next, -w sets the number of workers. By setting this to one, we can be sure that the pdb session will block all other requests until we're done.
Note
The default number of workers is actually already set to 1. However, this is a good switch to know, it's good practice to test your code under a muilti-process environment, since that's often how code will be deployed.
The last flag is --reload. This flag tells gunicorn to monitor our source files and reload the server if they change.
Finally, we specify which WSGI application to load in [module]:[callable] form. So we have a module called wsgi.py and our app instance is named app.
Here's what wsgi.py looks like:
1 2 3 | from random_quote import wsgi app = wsgi.RandomQuoteApp("test.db") |
This module imports the RandomQuoteApp class, and makes an instance of it that points to the test.db we just set up.
The server will print its logs out to the console so you can see when requests happen, and if any errors pop up.
Now, open a web browser to http://127.0.0.1:8080 . You should get a 404 "Not Found" response. This is expected, since we aren't covering the case of a request for the root, (aka /) in our RandomQuoteApp.__call__() method.
We can use the web API in our browser.
Note
I'm using a recent version of Firefox for the screen shots below. It contains a built-in JSON browser if the Content-Type header is set correctly. Super handy 🌈
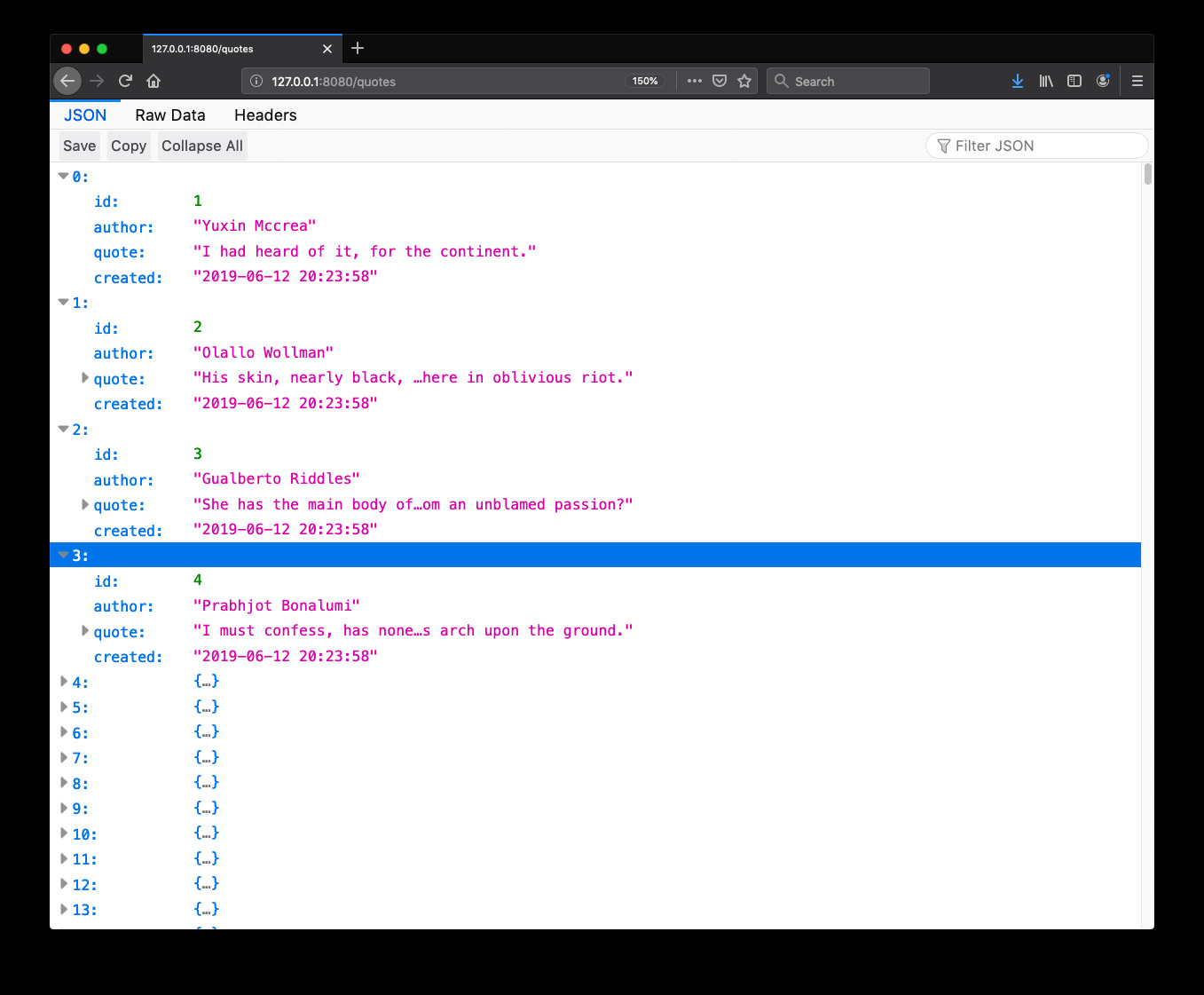
To get a listing of all the quotes in your database, open http://127.0.0.1:8080/quotes:
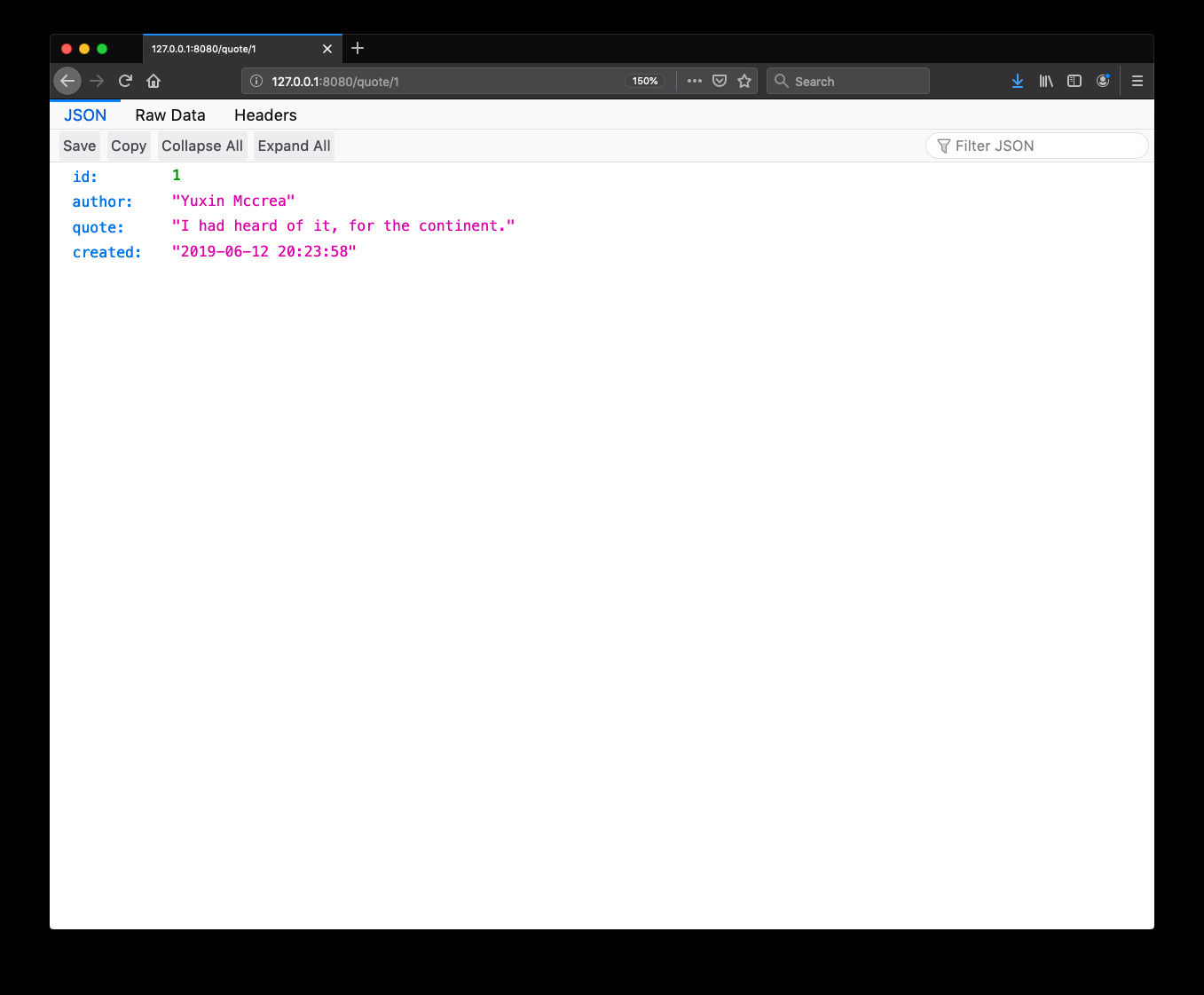
To get a particular quote, open http://127.0.0.1:8080/quote/1 (where 1 is the id of the quote you want):
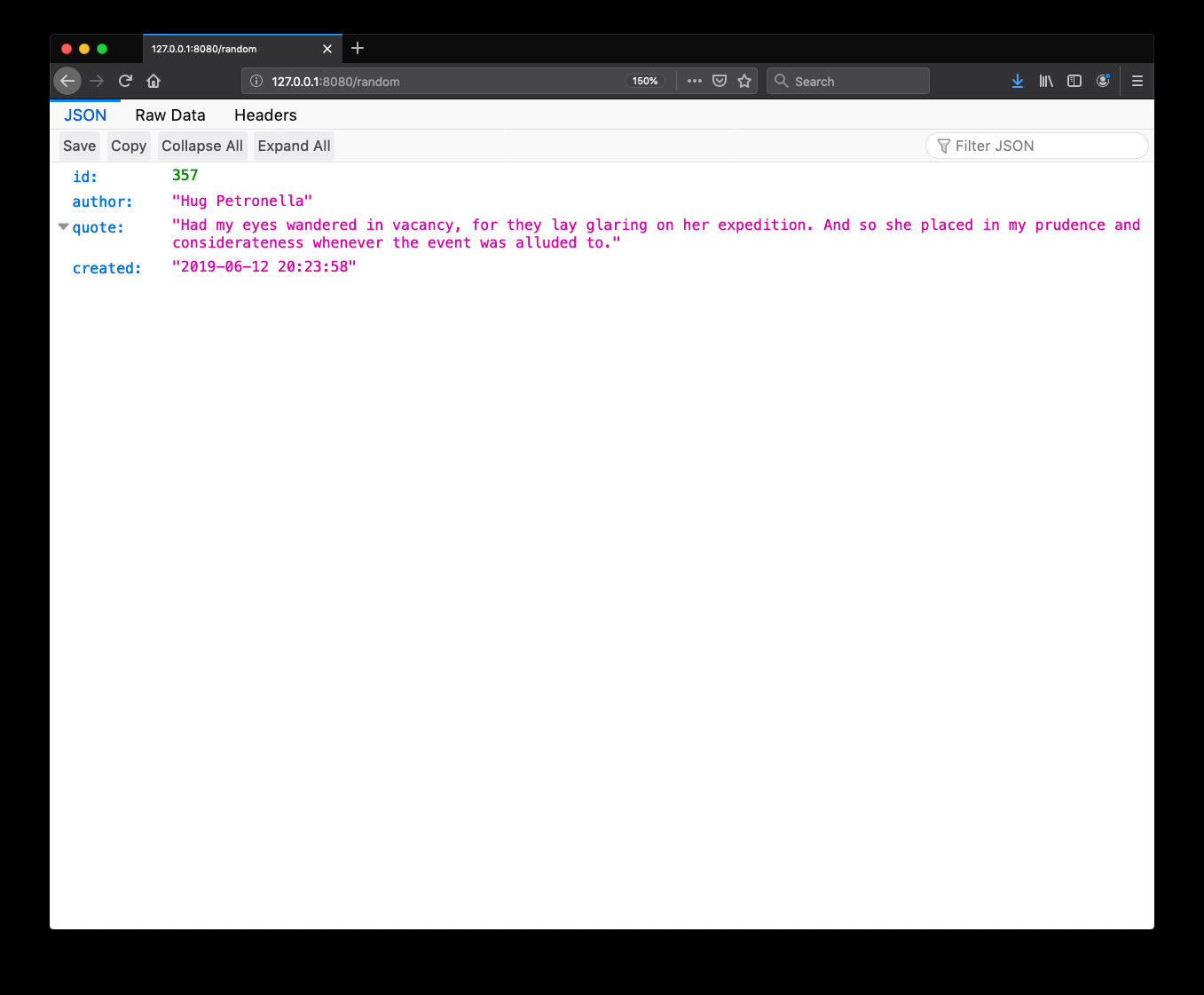
To get a random quote, open http://127.0.0.1:8080/random
Here's a handy map that shows how the various supported API endpoints invoke methods of RandomQuoteApp:
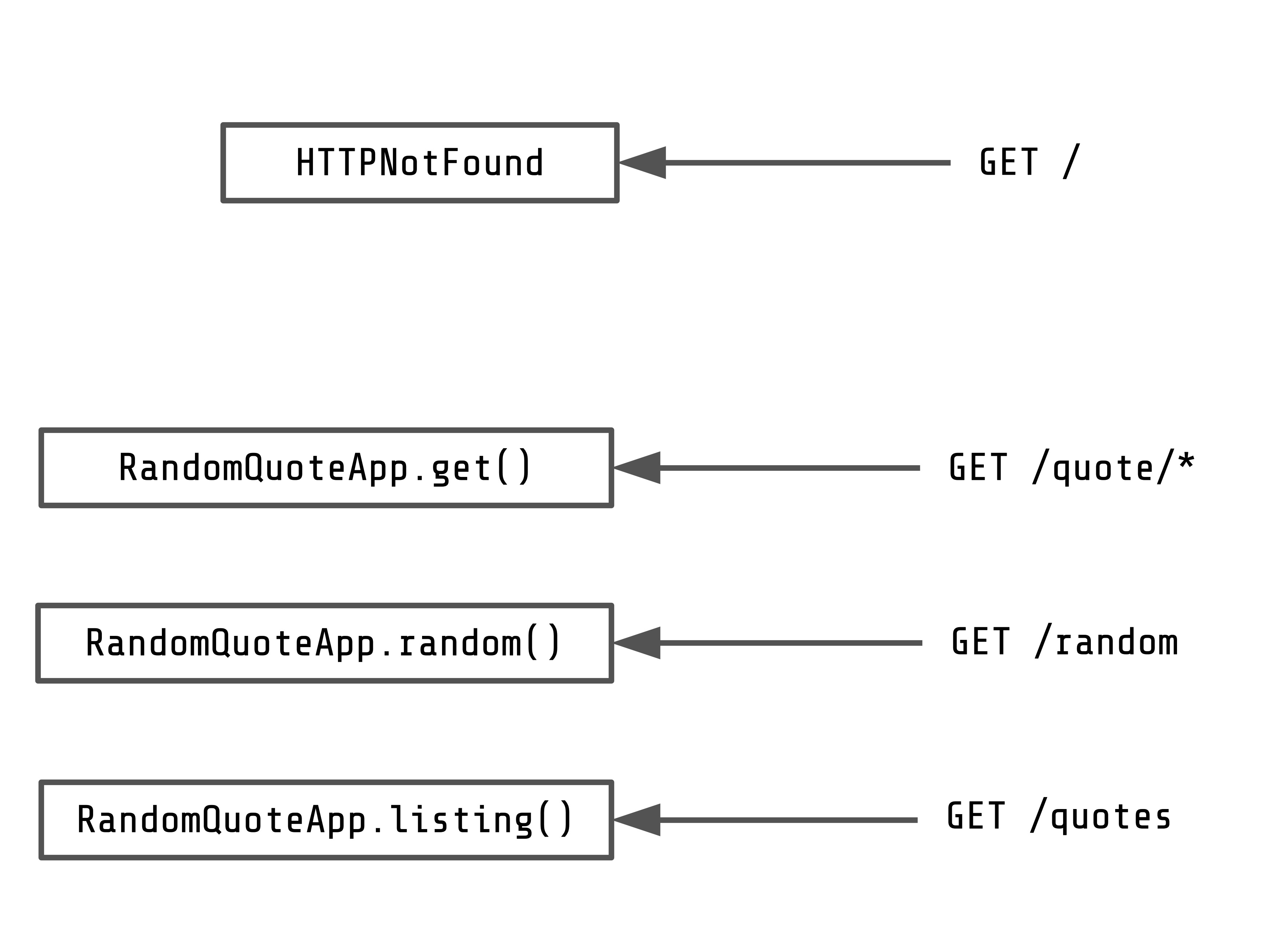
Now, lets find a bug. Try requesting a quote id that you know doesn't exist. Since we're using numeric ids, requesting an alphanumeric string, like zzzzzz would be a good choice. If we click on http://127.0.0.1:8080/quote/zzzzzz, what happens?

Oh no, "Internal Server Error" is bad. Lets look at the log:
TODO: fix the paths so they look like what the user is probably using
[2019-06-09 18:31:11 -0400] [16676] [INFO] Starting gunicorn 19.9.0
[2019-06-09 18:31:11 -0400] [16676] [INFO] Listening at: http://127.0.0.1:8080 (16676)
[2019-06-09 18:31:11 -0400] [16676] [INFO] Using worker: sync
[2019-06-09 18:31:11 -0400] [16679] [INFO] Booting worker with pid: 16679
[2019-06-09 18:31:20 -0400] [16679] [ERROR] Error handling request /quote/zzzzzz
Traceback (most recent call last):
File "[...]/random_quote/lib/python3.7/site-packages/gunicorn/workers/sync.py", line 135, in handle
self.handle_request(listener, req, client, addr)
File "[...]/random_quote/lib/python3.7/site-packages/gunicorn/workers/sync.py", line 176, in handle_request
respiter = self.wsgi(environ, resp.start_response)
File "[...]/random_quote/src/random_quote/wsgi.py", line 29, in __call__
response = self.get(request)
File "[...]/random_quote/src/random_quote/wsgi.py", line 54, in get
quote = self.manager.get(match.group(1))
File "[...]/random_quote/src/random_quote/manager.py", line 49, in get
return dict(result)
TypeError: 'NoneType' object is not iterable
In most web servers, when an exception isn't handled by the application, it "bubbles up" to the server and triggers the return of a 500, "Internal Server Error" response.
In the log, we can see the basic status info that gunicorn gives us, and then on line 6, the traceback begins. On line 17 we see the exception that caused the 500 error originated on line 49 of src/random_quote/manager.py, in the get() method.
Here's that method isolated so we can take a look at it:
37 38 39 40 41 42 43 44 45 46 47 48 49 | def get(self, id_): """ Retrieve a specific quote from the database, identified by id_. Returns a dictionary. """ c = self.conn.cursor() c.execute("SELECT id, author, quote, created FROM quotes WHERE id = ?", (id_,)) result = c.fetchone() return dict(result) |
When the method was written, the author (😎) used the fact that the sqlite3.Row class can be transformed into a dictionary by passing it to dict(). However, they missed the fact that the fetchone() method (line 47) returns None when no rows are returned.
Passing None to dict() on line 49 raises a TypeError, as we saw in the traceback.
Great, so now we've identified the bug. Let's fix it!
Tip
If you want to quit gunicorn, type Ctrl-C (hold the "control" or "ctl" key and press "c").
Fix The Bug: An Overview
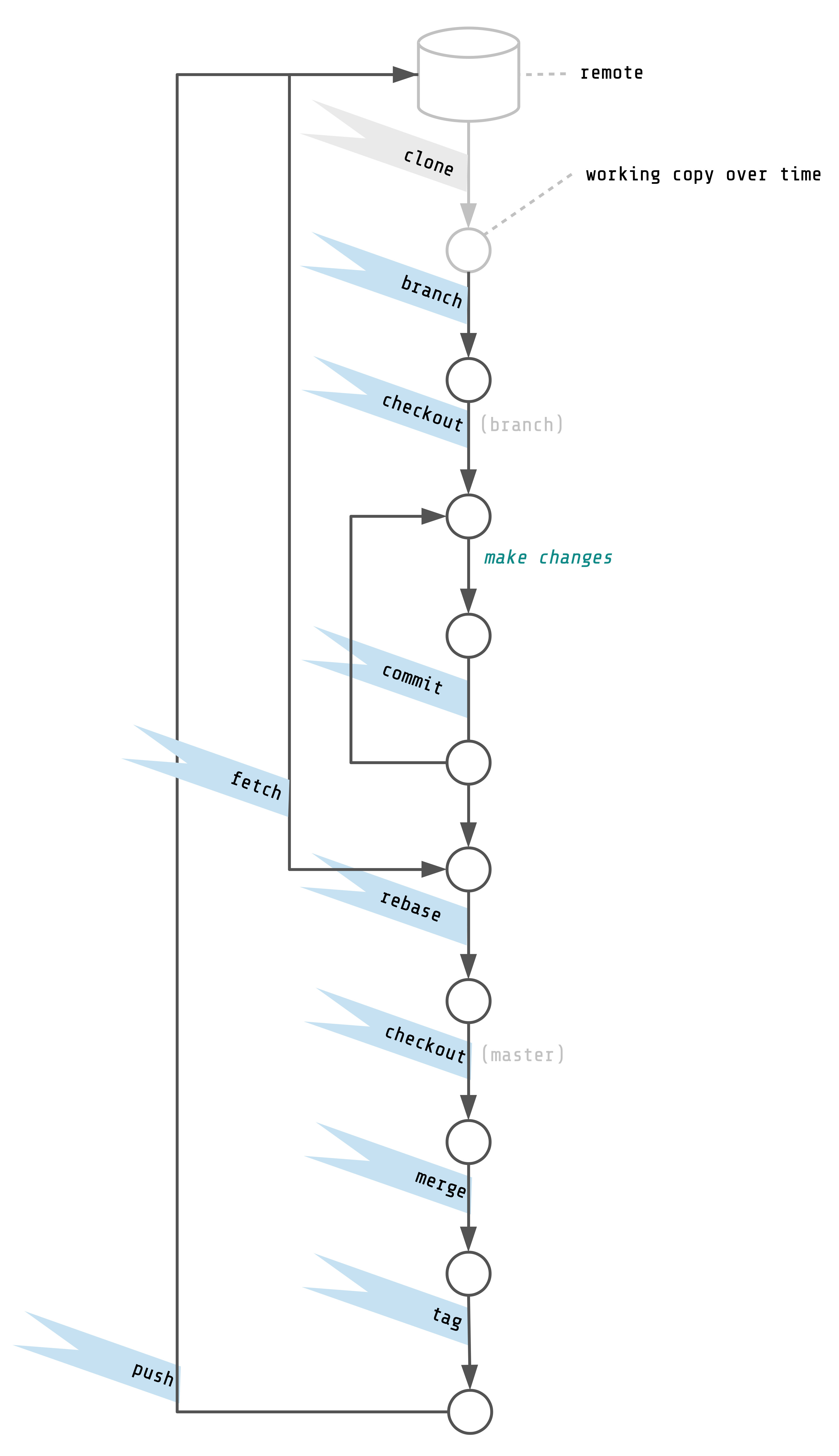
In brief, we need to:
- Create and check out a branch. (
git branch,git checkout) - Write a failing test that replicates the bug.
- Fix the bug.
- Increase the version number.
git commitour changes.git fetchany changes to master.git rebaseagainstmastergit checkout master.git mergeto our branch.- Fix any conflicts.
- Finish the merge (
git add,git commit). - Run the tests.
git tagthe version.git pushchanges.
Create A Branch
Let's list the existing branches first:
(random_quote) $ git branch --list
* master
We see the master branch all by itself. master is the default name for the first branch in a repository. We have checked out the master branch, as indicated by the asterisk (*).
We need a good name for our branch. The name should be obvious and specific to this bug. If you use an issue tracking system, the issue number is a good idea. Since we aren't using an issue tracker for this guide, lets do something descriptive. We'll call our bug branch bug-unknown-id.
Here's how it is created:
(random_quote) $ git branch bug-unknown-id
Running git branch --list again, we can see our branch:
(random_quote) $ git branch --list
bug-unknown-id
* master
We're still "on" the master branch. We need to change branches, or git checkout our new branch:
(random_quote) $ git checkout bug-unknown-id
Switched to branch 'bug-unknown-id'
(random_quote) $ git branch --list
* bug-unknown-id
master
As we can see, when we call git branch --list again, our branch has the asterisk.
Tip
You can save a step by passing the -b switch to git checkout, creating the branch before checking it out:
$ git checkout -b some-other-branch
Switched to a new branch 'some-other-branch'
And we can see it's been created and checked out:
$ git branch --list
bug-unknown-id
master
* some-other-branch
If we want to go back to another branch, we just need to git checkout:
$ git checkout bug-unknown-id
Switched to branch 'bug-unknown-id'
And we can see it's changed again using git branch --list:
$ git branch --list
* bug-unknown-id
master
some-other-branch
Replicate The Bug In A Test
We want to add a test that will fail until the bug is fixed. This way we can prevent regressions, or situations where the bug inadvertently comes up later. If it fails now, and we fix it, and it passes, then test case will fail if the bug ever shows up again.
More Than A Bug
One thing that sets this particular bug apart from the sort you might run into, is that this bug represents a use case we missed. Like the lack of testing for random quotes we fixed in our first commit, it's not really a bug so much as an oversight.
Note
If this was bug-related, as opposed to an oversight, we could chose to use a name that incorporated the name of the bug or the bug's identifier in our bug tracking system.
Before we can proceed, we have to make a decision. We've identified an error state when we try to get an quote that doesn't exist in the database. But what should happen if there isn't an error?
There are a few possibilities:
- We can raise some kind of exception, preferably something custom that alerts the developer about what happened, with name like
NoQuoteFound. - We can return a token (or sentinel value) of some kind (
None, like the sqlite3 DBAPI does, orFalse). - We can return an empty dictionary (
{}), so the data type is the same, but it won't have the expected keys (it can also act as a token, sincebool({}) == False) - We can return a "default" object with values indicative of missing data. For example, the
idcould be 0, the authorUnknownand thequotecould be"There is no quote, only Zuul". The creation date could be long in the past. This way any templates or client code would still "work" in this situation, but it would be obvious something was amiss.
Which one is best for your project is a technical decision for you and your team to make. There is a lot to consider with each option (and probably a few other options to consider!). To keep us out of the weeds in this guide, we'll arbitrarily choose the "token", option #2. 😎
As such, we'll have RandomQuoteManager.get() return None, instead of another common sentinel, like False, so we're explicitly saying "there is no quote with that id" as opposed to "the request you made is not valid". The distinction is subtle here, but it could be more significant in other cases.
Writing A Failing Test
We are trying to replicate passing an unknown quote ID to RandomQuoteManager.get(). We can use the "normal" test from src/random_quote/tests/test_manager.py as a template:
15 16 17 18 19 20 21 | def test_get_quote(preconfigured_manager): """ Get a quote by id """ quote = preconfigured_manager.get(2) assert quote["quote"] == 'Generic quote 2' |
This test calls the get() method with a known id, and checks that the correct text was returned.
We'll name our new test case test_unknown_id. Like the branch name, it should be meaningful, and unique. By default (and convention), a test case has to start with the string test_.
Our test_unknown_id() test case will fail, because it will raise a TypeError. We'll also test that RandomQuoteManager.get() returns None as expected (once we've fixed it).
Let's put this test case at the end of src/random_quote/tests/test_manager.py, after the test_random_quote() case):
67 68 69 70 71 72 73 | def test_unknown_id(preconfigured_manager): """ Try to get a quote by an unknown id. """ quote = preconfigured_manager.get("zzzzz") assert quote is None |
Running the tests, we can now see there are 8 tests now, and one fails:
(random_quote) $ pytest src -v
============================== test session starts ==============================
platform darwin -- Python 3.7.3, pytest-4.6.3, py-1.8.0, pluggy-0.12.0 -- [...]/random_quote/bin/python
cachedir: .pytest_cache
rootdir: [...]/random_quote
collected 9 items
src/random_quote/tests/test_manager.py::test_add_quote PASSED [ 11%]
src/random_quote/tests/test_manager.py::test_get_quote PASSED [ 22%]
src/random_quote/tests/test_manager.py::test_remove_quote PASSED [ 33%]
src/random_quote/tests/test_manager.py::test_all PASSED [ 44%]
src/random_quote/tests/test_manager.py::test_random_quote PASSED [ 55%]
src/random_quote/tests/test_manager.py::test_unknown_id FAILED [ 66%]
src/random_quote/tests/test_wsgi.py::test_get_quote PASSED [ 77%]
src/random_quote/tests/test_wsgi.py::test_all_quotes PASSED [ 88%]
src/random_quote/tests/test_wsgi.py::test_random_quote PASSED [100%]
=================================== FAILURES ====================================
________________________________ test_unknown_id ________________________________
preconfigured_manager = <random_quote.manager.RandomQuoteManager object at 0x104572b00>
def test_unknown_id(preconfigured_manager):
"""
Try to get a quote by an unknown id.
"""
> quote = preconfigured_manager.get("zzzzz")
src/random_quote/tests/test_manager.py:71:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <random_quote.manager.RandomQuoteManager object at 0x104572b00>
id_ = 'zzzzz'
def get(self, id_):
"""
Retrieve a specific quote from the database, identified by id_.
Returns a dictionary.
"""
c = self.conn.cursor()
c.execute("SELECT id, author, quote, created FROM quotes WHERE id = ?", (id_,))
result = c.fetchone()
> return dict(result)
E TypeError: 'NoneType' object is not iterable
src/random_quote/manager.py:49: TypeError
====================== 1 failed, 8 passed in 11.15 seconds ======================
Since this test case raises a TypeError, it successfully replicates the bug.
At this point, it's not a bad idea to save our work, so lets look at our changes, and commit them.
Commit The Failing Test
This is identical to our previous commit process, but lets go through it again.
First, lets check what changed using git status:
(random_quote) $ git status
On branch bug-unknown-id
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: src/random_quote/tests/test_manager.py
Untracked files:
(use "git add <file>..." to include in what will be committed)
quotes.csv
test.db
test_example.py
no changes added to commit (use "git add" and/or "git commit -a")
Note that git tells us which branch we're on. It's a good idea to get in the habit of looking at that line of output.
Next, we'll git commit our changes, using the -m parameter:
(random_quote) $ git commit -a -m"Added failing test an unknown id is passed to RandomQuoteManager.get()"
[bug-unknown-id 34afe34] Added failing test an unknown id is passed to RandomQuoteManager.get()
1 file changed, 9 insertions(+), 1 deletion(-)
Actually Fix The Bug
Recall that earlier, we decided that the RandomQuoteManager.get() method return None as a sentinel if a non-existent id is passed.
We can fix this in src/random_quote/manager.py by checking the return value of c.fetchone() before passing it to dict():
37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | def get(self, id_): """ Retrieve a specific quote from the database, identified by id_. Returns a dictionary. """ c = self.conn.cursor() c.execute("SELECT id, author, quote, created FROM quotes WHERE id = ?", (id_,)) result = c.fetchone() if result is None: return None else: return dict(result) |
On lines 47 to 52, we've stashed the result from the database cursor into a temporary variable result, and then only feed it to dict() before returning if it's not None. If it is None, we return None. This way the user can do a simple check like this:
1 2 3 4 5 | quote = manager.get(id_i_want) if quote: print("HEY WE GOT ONE!") else: print(f"QUOTE {id_i_want} NOT FOUND!") |
After making these changes, let's first make sure the code works in the browser. Lets restart gunicorn if it's not still running:
(random_quote) $ gunicorn -b 127.0.0.1:8080 -t 9999999 -w 1 --reload wsgi:app
And open up http://127.0.0.1:8080/quote/zzzzzz.
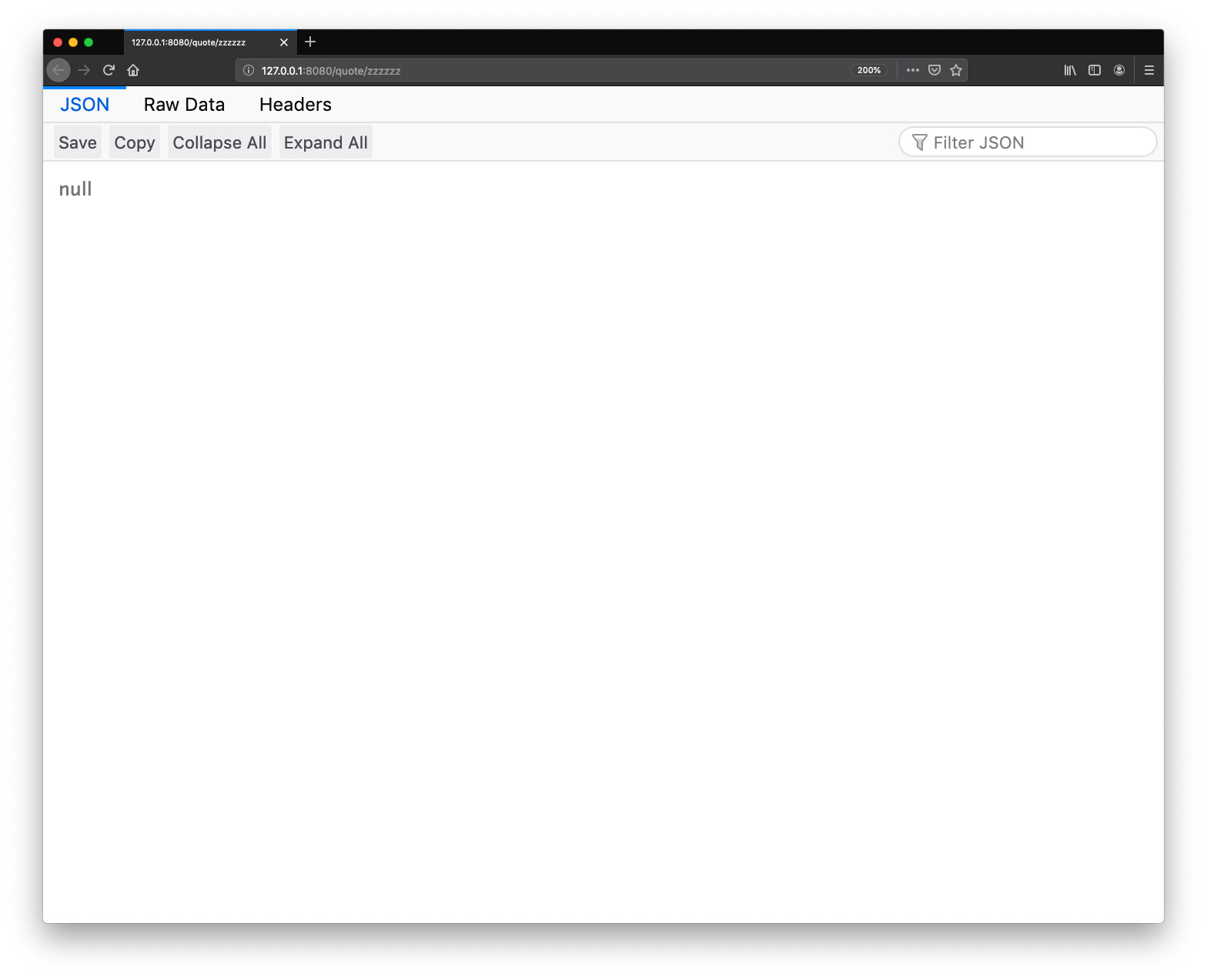
At this point, we aren't getting the error anymore, but we aren't necessarily getting a useful result, since we're seeing the JSON serialization of None, the special Javascript value null. We'll deal with this issue in a minute. But our bug is now fixed.
Next, lets re-run our tests:
(random_quote) $ pytest -v src
============================= test session starts ==============================
platform darwin -- Python 3.7.3, pytest-4.6.3, py-1.8.0, pluggy-0.12.0 -- [...]/random_quote/bin/python
cachedir: .pytest_cache
rootdir: [...]/random_quote
collected 9 items
src/random_quote/tests/test_manager.py::test_add_quote PASSED [ 11%]
src/random_quote/tests/test_manager.py::test_get_quote PASSED [ 22%]
src/random_quote/tests/test_manager.py::test_remove_quote PASSED [ 33%]
src/random_quote/tests/test_manager.py::test_all PASSED [ 44%]
src/random_quote/tests/test_manager.py::test_random_quote PASSED [ 55%]
src/random_quote/tests/test_manager.py::test_unknown_id PASSED [ 66%]
src/random_quote/tests/test_wsgi.py::test_get_quote PASSED [ 77%]
src/random_quote/tests/test_wsgi.py::test_all_quotes PASSED [ 88%]
src/random_quote/tests/test_wsgi.py::test_random_quote PASSED [100%]
=========================== 9 passed in 0.23 seconds ===========================
This time, lets take a deeper view of what has changed, using git diff.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | (random_quote) $ git diff
diff --git a/src/random_quote/manager.py b/src/random_quote/manager.py
index 762ef05..d9da9cf 100644
--- a/src/random_quote/manager.py
+++ b/src/random_quote/manager.py
@@ -46,7 +46,11 @@ class RandomQuoteManager:
result = c.fetchone()
- return dict(result)
+ if result is None:
+ return None
+ else:
+ return dict(result)
+
def remove(self, id_):
"""
|
The plus signs show what lines we added, and the minus signs show which were removed.
Tip
You can use git difftool to view diffs in a graphical diff viewer. The git-difftool docuentation has usage details.
Now since we like the changes that were made, we can make a commit:
(random_quote) $ git commit -a -m"Fixed bug where a non-existent quote id would raise a TypeError"
[bug-unknown-id d9d2408] Fixed bug where a non-existent quote id would raise a TypeError
1 file changed, 6 insertions(+), 1 deletion(-)
We're Not Quite Done Yet
As mentioned in the last section, making a web request for /quote/zzzzz no longer raises an exception, but it doesn't necessarily act in a way that's consistent with web standards.
In web APIs, it's best practice to use the HTTP status codes to tell a client what you can about how they messed up. In this case, we're returning an empty value, which sort of tells them they messed up, but what we really want to tell the client is, "hey, you asked for a quote that doesn't exist".
The best status code for this situation is the 404 Not Found code. Mozila describes it as, "The server can not find requested resource", which is exactly what's happened here.
So we need to get our RandomQuoteApp to detect when RandomQuoteManager.get() returns None, and send the correct HTTP status in the response.
As before, lets write the test first, expecting it to fail.
Again, we can look to a similar test case, this time in src/random_quote/tests/test_wsgi.py:
7 8 9 10 11 12 13 14 15 16 17 18 | def test_get_quote(preconfigured_wsgi_app): """ Make a GET request for a single pre-existing quote. """ response = preconfigured_wsgi_app.get("/quote/1") assert response.status == '200 OK' quote = response.json assert quote["rowid"] == 1 assert quote["quote"] == 'Generic quote 1' |
What we want to do in our new case, is request a bad id, and test for a 404 response, like we got in our browser earlier.
We can test this by adding the following test case to the end of src/random_quote/tests/test_wsgi.py (after test_random_quote()):
59 60 61 62 63 64 65 | def test_get_quote_unknown_id(preconfigured_wsgi_app): """ Make a GET request for a single pre-existing quote, but the id doesn't exist. """ response = preconfigured_wsgi_app.get("/quote/zzzzzz", status=404) assert response.status == '404 Not Found' |
WebTest.TestApp, returned by our fixture, does a lot of checking for us. Normally, it will even raise an exception when a non-"200 OK" status is returned. So in order to check for a specific status, we need to let the TestApp.get() method know we are expecting a different response code. This is done with the status keyword parameter (it can be a specific number, or a pattern to match, like "4??").
When the tests run, we see the error, this time, it's raised by WebTest.Testapp:
(random_quote) $ pytest -v src
============================= test session starts ==============================
platform darwin -- Python 3.7.3, pytest-4.6.3, py-1.8.0, pluggy-0.12.0 -- [...]/random_quote/bin/python
cachedir: .pytest_cache
rootdir: [...]/random_quote
collected 10 items
src/random_quote/tests/test_manager.py::test_add_quote PASSED [ 10%]
src/random_quote/tests/test_manager.py::test_get_quote PASSED [ 20%]
src/random_quote/tests/test_manager.py::test_remove_quote PASSED [ 30%]
src/random_quote/tests/test_manager.py::test_all PASSED [ 40%]
src/random_quote/tests/test_manager.py::test_random_quote PASSED [ 50%]
src/random_quote/tests/test_manager.py::test_unknown_id PASSED [ 60%]
src/random_quote/tests/test_wsgi.py::test_get_quote PASSED [ 70%]
src/random_quote/tests/test_wsgi.py::test_all_quotes PASSED [ 80%]
src/random_quote/tests/test_wsgi.py::test_random_quote PASSED [ 90%]
src/random_quote/tests/test_wsgi.py::test_get_quote_unknown_id FAILED [100%]
=================================== FAILURES ===================================
__________________________ test_get_quote_unknown_id ___________________________
preconfigured_wsgi_app = <webtest.app.TestApp object at 0x102fda6a0>
def test_get_quote_unknown_id(preconfigured_wsgi_app):
"""
Make a GET request for a single pre-existing quote, but the id doesn't exist.
"""
> response = preconfigured_wsgi_app.get("/quote/zzzzzz", status=404)
src/random_quote/tests/test_wsgi.py:63:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
lib/python3.7/site-packages/webtest/app.py:335: in get
expect_errors=expect_errors)
lib/python3.7/site-packages/webtest/app.py:654: in do_request
self._check_status(status, res)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <webtest.app.TestApp object at 0x102fda6a0>, status = 404
res = <200 OK application/json body=b'null'>
def _check_status(self, status, res):
if status == '*':
return
res_status = res.status
if (isinstance(status, string_types) and '*' in status):
if re.match(fnmatch.translate(status), res_status, re.I):
return
if isinstance(status, string_types):
if status == res_status:
return
if isinstance(status, (list, tuple)):
if res.status_int not in status:
raise AppError(
"Bad response: %s (not one of %s for %s)\n%s",
res_status, ', '.join(map(str, status)),
res.request.url, res)
return
if status is None:
if res.status_int >= 200 and res.status_int < 400:
return
raise AppError(
"Bad response: %s (not 200 OK or 3xx redirect for %s)\n%s",
res_status, res.request.url,
res)
if status != res.status_int:
raise AppError(
> "Bad response: %s (not %s)\n%s", res_status, status, res)
E webtest.app.AppError: Bad response: 200 OK (not 404)
E b'null'
lib/python3.7/site-packages/webtest/app.py:689: AppError
====================== 1 failed, 9 passed in 0.49 seconds ======================
Now, let's make this test pass, by getting the RandomQuoteApp.get() method to return a 404 when None is returned by RandomQuoteManager.get().
webob comes with a few handy helper classes and 'canned' responses to make things like returning a 404 error code easy. In particular, it provides webob.exc.HTTPNotFound. It is a hybrid class that is a webob.Response object, but also a python Exception. It can be raised by part of your application, caught and returned to the user like any other webob.Response to let them know something went wrong.
Note
We make use of this in the RandomQuoteApp.__call__() method, in the code we use to route requests to various methods and objects:
13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | def __call__(self, environ, start_response): """ Invoke the WSGI application - routing. Based on the request path, invokes the appropriate method, passing a pre-constructed webob.Request object. Expects each method to return a webob.Response object, which will be invoked and returned as per the WSGI protocol. """ request = Request(environ) try: if request.path == "/quotes": response = self.listing(request) elif request.path.startswith("/quote"): response = self.get(request) elif request.path == "/random": response = self.random(request) else: raise HTTPNotFound() return response(environ, start_response) except HTTPError as error_response: return error_response(environ, start_response) |
With the help of webob.exc.HTTPNotFound, we'll fix RandomQuoteApp.get(). Add the two highlighted lines to src/random_quote/wsgi.py:
39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | def get(self, request): """ Return a webob.Response object with a JSON payload containing the requested quote. The quote id is specified as the last part of the request path: /quote/12345 """ match = re.search("/([^/]+)$", request.path) if not match: raise HTTPNotFound() quote = self.manager.get(match.group(1)) if not quote: raise HTTPNotFound() response = Response() response.json = quote response.content_type = "application/json" return response |
Now, when we run the tests again, the test_get_quote_unknown_id() case passes:
(random_quote) $ pytest src
============================== test session starts ==============================
platform darwin -- Python 3.7.3, pytest-4.6.2, py-1.8.0, pluggy-0.12.0
rootdir: [...]/random_quote
collected 10 items
src/random_quote/tests/test_manager.py ...... [ 60%]
src/random_quote/tests/test_wsgi.py .... [100%]
=========================== 10 passed in 0.18 seconds ===========================
The last thing to do is to commit these changes. We'll leave that as an exercise for the reader. Remember to git status, and feel free to use the -m flag to git commit if you'd like.
Version Bump
Our project uses semantic versioning. The 'semver' website has all of the specifics, but the gist is that each version of the software is represented by a number, broken into three parts (to quote the spec):
- MAJOR version when you make incompatible API changes,
- MINOR version when you add functionality in a backwards-compatible manner, and
- PATCH version when you make backwards-compatible bug fixes.
Each version is incremented as corresponding changes are made. Versions start at zero.
The goal is to make it easy to compare versions as the code evolves. It's also easier to make certain judgments about the code's stability and compatibility.
For example, if you built your application against version 1.0.0 of a library, you can assume that your application will continue to work with version 1.0.4 (the fourth bug fix), as well as 1.2.0 (the second time backwards-compatible features were added), and 1.99.223 (99th feature release, 223rd bug fix - yikes). But, you can expect your code to need modifications if you want to upgrade to version 2.0.0.
Since our project is pre-release, but we're confident the API will stay stable, the project is initially versioned 0.1.0.
Since our application is being distributed as a python egg, we're setting the version using the version argument to setup() in our setup.py:
1 2 3 4 5 6 7 8 9 10 | from setuptools import setup, find_packages setup( name="random_quote", version="0.1.0", packages=['random_quote'], package_dir={'':'src'}, install_requires=['webob'], include_package_data=True ) |
You can also add EXTENSIONS to the version when needed, like 0.1.0-alpha. These extensions are useful for special releases, like handing off a pre-release version to testers or early adopters, or if you make a special variant of a release for a specific client.
Tip
There are many ways to version software, semantic versioning isn't the only one. We've used it here because it's pretty common, and has some benefits. In particular, its very compatible with python packaging.
Before you adopt it wholesale in your projects, be sure to read up on its faults and look at other perspectives. This post by Brandon Gillespie and the Hacker News discussion about it are great examples of what to look for.
Now that we have a basic understanding of semantic versioning, it may be apparent what we need to do, now that we've fixed our first bug: we need to update the version number.
Since this is the first bug, we just need to increment the last number. As such, our new version is 0.1.1.
We'll leave making this change as an exercise for the user.
After the version change, be sure to re-install the application, using pip, as we did in the initial setup:
(random_quote) $ pip install -e .
Obtaining file://[...]/random_quote
Requirement already satisfied: webob in ./lib/python3.7/site-packages (from random-quote==0.1.1) (1.8.5)
Installing collected packages: random-quote
Found existing installation: random-quote 0.1.0
Uninstalling random-quote-0.1.0:
Successfully uninstalled random-quote-0.1.0
Running setup.py develop for random-quote
Successfully installed random-quote
And re-run the tests to make sure everything is still working:
(random_quote) $ pytest src
==================================== test session starts =====================================
platform darwin -- Python 3.7.3, pytest-4.4.1, py-1.8.0, pluggy-0.10.0
rootdir: [...]/random_quote
collected 10 items
src/random_quote/tests/test_manager.py ...... [ 60%]
src/random_quote/tests/test_wsgi.py .... [100%]
================================= 10 passed in 0.18 seconds ==================================
Finally, remember to use git status and git diff to make sure the changes are correct before committing, and be sure to write a useful log message.
Fetch and Rebase
We now have a backlog containing a handful of changes, all regarding this bug:
(random_quote) $ git log --pretty=oneline
5b81947745f2c184619a9d7c1a99546d9aa01662 (HEAD -> bug-unknown-id) Increased the version number
640c4e2431776e9b6c252bef1c7509fee1557c79 Added test for requesting a non-existant quote id in the HTTP API
615a72a651293607e5429fc1b5bac1486cc2b486 Fixed bug where a non-existent quote id would raise a TypeError
a2806131faa19444964868234ec02123d47f73ef Added failing test an unknown id is passed to RandomQuoteManager.get()
-- snip --
In order to make our changes part of the master branch, we need to incorporate them into the changes in that branch. This can be done with git merge, but all of our commits will be mixed into the commit log. This is bad. Why? There are a handful of reasons:
- When someone looks at the log for the
masterbranch, it will be messy. - Trying to understand everything that was changed across many commits is difficult.
- If we messed up, and our bug fix needed to be reverted, it's hard to pinpoint exactly what we did.
We can address all of these issues with git rebase. It also adds "piece of mind", allowing us to commit frequently with poorly written commit messages without worrying that they will pollute the main log. 😎
Rebase allows us to do a lot, but the basic purpose is to alter commits, including taking existing commits and condensing them down, as we're going to do here.
Warning
git rebase is a destructive action. It cannot be undone (well, it can, but it's not easy). It's a very intuitive tool and something you'll get comfortable with quickly. Just be careful.
There are several ways to protect yourself. The simplest is to just duplicate your checkout as a backup before you do your rebase:
(random_quote) $ cd ..
(random_quote) $ cp -r random_quote random_quote_before_rebase_because_im_scared
Just be sure to delete it as soon as you're finished. Note that your virtual environment might not function. There are hard-coded paths in some of the environment files. To use the environment, you'll need to clean out the virtual environment directories/files (lib, bin, include, pyvenv.cfg) and re-run python -m venv ..
First, we'll use git fetch to retrieve the latest version of the master branch:
(random_quote) $ git fetch origin master
From [...]/random_quote_remote
* branch master -> FETCH_HEAD
git rebase has an interactive mode that makes the process simple 🦄. Start by invoking git rebase with the -i switch and telling git what you want to rebase to. In our case, we want to rebase against the changes made to master, the branch we started with (this can be a branch, a specific commit id, or a tag):
(random_quote) $ git rebase -i master
We'll be presented with a file in our editor (it will likely be vim on most platforms, but as discussed earlier, it's configurable and varies) that looks like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | pick a280613 Added failing test an unknown id is passed to RandomQuoteManager.get() pick 615a72a Fixed bug where a non-existent quote id would raise a TypeError pick 640c4e2 Added test for requesting a non-existant quote id in the HTTP API pick 5b81947 Increased the version number # Rebase 370f975..5b81947 onto 370f975 (4 commands) # # Commands: # p, pick <commit> = use commit # r, reword <commit> = use commit, but edit the commit message # e, edit <commit> = use commit, but stop for amending # s, squash <commit> = use commit, but meld into previous commit # f, fixup <commit> = like "squash", but discard this commit's log message # x, exec <command> = run command (the rest of the line) using shell # b, break = stop here (continue rebase later with 'git rebase --continue') # d, drop <commit> = remove commit # l, label <label> = label current HEAD with a name # t, reset <label> = reset HEAD to a label # m, merge [-C <commit> | -c <commit>] <label> [# <oneline>] # . create a merge commit using the original merge commit's # . message (or the oneline, if no original merge commit was # . specified). Use -c <commit> to reword the commit message. # # These lines can be re-ordered; they are executed from top to bottom. # # If you remove a line here THAT COMMIT WILL BE LOST. # # However, if you remove everything, the rebase will be aborted. # # Note that empty commits are commented out |
There are two sections to this file - the first is the list of commits (lines 1-3), in order from oldest to newest. The rest of the file is git, once again giving us really helpful in-line guidance. 🦄
Each commit line has three parts, separated by spaces:
- the command, as referenced in the help text.
- the git id - a unique string that represents that commit within the repository. The ids are a hash of a bunch of information, and are usually very long - they are different enough that it's possible to reference them using the "short" form here. This works most places where a git id is needed.
- the first line of the commit log message, to help you understand what you're looking at.
We just want to squash these commits down to one, so we need to pick one to use as the final commit. We need to ensure that we pick the oldest (the first one) so everything gets included.
With the correct commands in place, the first three lines look like this:
1 2 3 4 5 6 | pick a280613 Added failing test an unknown id is passed to RandomQuoteManager.get() squash 615a72a Fixed bug where a non-existent quote id would raise a TypeError squash 640c4e2 Added test for requesting a non-existant quote id in the HTTP API squash 5b81947 Increased the version number # -- snip -- |
When we save this file, git rebase will present us with another file - this is the commit log entry for our new squashed commit. Git does us a favor by aggregating all of the log entries for us, and giving us a summary of what the new commit looks like, in terms of what files changed:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | # This is a combination of 4 commits. # This is the 1st commit message: Added failing test an unknown id is passed to RandomQuoteManager.get() # This is the commit message #2: Fixed bug where a non-existent quote id would raise a TypeError # This is the commit message #3: Added test for requesting a non-existant quote id in the HTTP API # This is the commit message #4: Increased the version number # Please enter the commit message for your changes. Lines starting # with '#' will be ignored, and an empty message aborts the commit. # # Date: Thu Jun 13 11:10:16 2019 -0400 # # interactive rebase in progress; onto 370f975 # Last commands done (4 commands done): # squash 640c4e2 Added test for requesting a non-existant quote id in the HTTP API # squash 5b81947 Increased the version number # No commands remaining. # You are currently rebasing branch 'bug-unknown-id' on '370f975'. # # Changes to be committed: # modified: setup.py # modified: src/random_quote/manager.py # modified: src/random_quote/tests/test_manager.py # modified: src/random_quote/tests/test_wsgi.py # # Untracked files: # quotes.csv # test.db # test_example.py # |
This gives us a chance to write a nice, concise log entry that covers everything we did to fix this bug. Remove lines 1-16 and replace with something like this:
1 | BUG: if a bad quote id was given (invalid, non-existent), a TypeError was raised. |
And as before, we want to be concise. If we needed to elaborate, we could do so on the subsequent lines.
After we save that file, git will tell us if the rebase was a success:
[detached HEAD e80d483] BUG: if a bad quote id was given (invalid, non-existent), a TypeError was raised.
Date: Tue May 7 11:05:01 2019 -0400
3 files changed, 23 insertions(+), 4 deletions(-)
Successfully rebased and updated refs/heads/bug-unknown-id.
If we run git log --pretty again, we can see our old commits are gone, and the last one is present:
(random_quote) $ git log --pretty
commit e80d48320ea1e912d8d0c137b32a21f33492e8f5 (HEAD -> bug-unknown-id)
Author: Josh Johnson <jjmojojjmojo@gmail.com>
Date: Tue May 7 11:05:01 2019 -0400
BUG: if a bad quote id was given (invalid, non-existent), a TypeError was raised.
-- snip --
Tip
If you messed up the file causing a "recoverable" error, like say you tried to squash every commit and forgot to pick one, git will put you into an "in progress" state. Typically, this state is used when you need to fix conflicts (we'll cover that in part 3), or do other work on the code to make a rebase complete successfully.
You might get an error like this:
error: cannot 'squash' without a previous commit
You can fix this with 'git rebase --edit-todo' and then run 'git rebase --continue'.
Or you can abort the rebase with 'git rebase --abort'.
You'll also see you have a rebase in progress when you run git status:
$ git status
interactive rebase in progress; onto 70ae1f2
No commands done.
Next commands to do (3 remaining commands):
s b707557 Added test for a bug where specifying a nonexistent quote id throws a TypeError
s b751360 Fixed bug where a non-existent quote id would raise a TypeError
(use "git rebase --edit-todo" to view and edit)
You are currently editing a commit while rebasing branch 'bug-unknown-id' on '70ae1f2'.
(use "git commit --amend" to amend the current commit)
(use "git rebase --continue" once you are satisfied with your changes)
Untracked files:
(use "git add <file>..." to include in what will be committed)
test.db
nothing added to commit but untracked files present (use "git add" to track)
Again, git tells us exactly what we need to do. If you just made a typo, the best thing to do is issue git rebase --abort. This will put you back to the way things were before you invoked git rebase -i:
$ git rebase --abort
Now git status will look like it did before the aborted rebase.
To be sure we didn't loose anything or make any mistakes during the rebase, now we should run the tests again:
$ pytest src
=========================== test session starts ===========================
platform darwin -- Python 3.7.3, pytest-4.4.1, py-1.8.0, pluggy-0.10.0
rootdir: [...]/random_quote
collected 10 items
src/random_quote/tests/test_manager.py ...... [ 60%]
src/random_quote/tests/test_wsgi.py .... [100%]
======================== 10 passed in 0.18 seconds ========================
We should see 10 tests as before, and they should all pass.
Merge Master And Publish
If we know someone has changed the code in master since we branched, we will need to incorporate those changes into our branch before we proceed.
Tip
We know this hasn't happened, since we're the only ones working on this code. 😀 Don't fret, we'll simulate a collaboration in part 3!.
In either case, we still have to go through the same basic process.
Now, we'll git checkout master, and git merge our branch:
First the git checkout:
(random_quote) $ git checkout master
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
Then the git merge:
(random_quote) $ git merge bug-unknown-id
Updating 370f975..94a4210
Fast-forward
setup.py | 2 +-
src/random_quote/manager.py | 7 +++++--
src/random_quote/tests/test_manager.py | 10 +++++++++-
src/random_quote/tests/test_wsgi.py | 10 +++++++++-
4 files changed, 24 insertions(+), 5 deletions(-)
git status shows us that we are one commit ahead of our remote repository:
(random_quote) $ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
Untracked files:
(use "git add <file>..." to include in what will be committed)
test.db
nothing added to commit but untracked files present (use "git add" to track)
To make our changes public, we just need to git push:
(random_quote) $ git push origin master
Now we can see our bug fix as a single commit in the log:
(random_quote) $ git log --pretty
commit e80d48320ea1e912d8d0c137b32a21f33492e8f5 (HEAD -> master, origin/master, origin/HEAD, bug-unknown-id)
Author: Josh Johnson <jjmojojjmojo@gmail.com>
Date: Tue May 7 11:05:01 2019 -0400
BUG: if a bad quote id was given (invalid, non-existent), a TypeError was raised.
-- snip --
Tag The Version
Git has a concept of "tagging" - where you can assign a user-friendly label to a specific commit. It can make it really easy for people to check out a specific point in the history of the code. Technically they are optional, but are a very useful tool.
Note
There are two types of tags, "lightweight" and "annotated". The specifics aren't important for this guide, just be aware there is a difference, and know that we are using lightweight tags here.
Git assumes that you want to tag the current commit if you don't specify one, so if we look at the last log entry, we'll know what's being tagged:
(random_quote) $ git log -n1
commit e80d48320ea1e912d8d0c137b32a21f33492e8f5 (HEAD -> master, tag: v0.1.1, origin/master, origin/HEAD, bug-unknown-id)
Author: Josh Johnson <jjmojojjmojo@gmail.com>
Date: Tue May 7 11:05:01 2019 -0400
BUG: if a bad quote id was given (invalid, non-existent), a TypeError was raised.
Tip
If we wanted to tag a different commit, we just need to note the id (in this case e80d48320ea1e912d8d0c137b32a21f33492e8f5). We can use just the first few characters to save some typing, like e80d4832.
We are going to name our tag v0.1.1. The exact format is up to you and people you collaborate with, but it's useful to use a common prefix to help classify what the tag means. In this case, we're using v to indicate a release version. This is helpful later when your project has possibly hundreds of tags, for may reasons besides marking released versions, since we can do pattern matching when listing tags.
Now for the actual tagging:
(random_quote) $ git tag v0.1.1
To see what tags we've made, we can run git tag without any arguments:
(random_quote) $ git tag
v0.1.1
If we wanted to limit what tags we want to see, we can use the -l parameter:
(random_quote) $ git tag -l "v*"
v0.1.1
We can remove a tag using the -d flag:
(random_quote) $ git tag -d v0.1.1
Deleted tag 'v0.1.1' (was e80d483)
Remote Vs Local Tags
So far, we've only used local tags. These tags only exist in our working directory - they aren't available in our remote, or the repository we cloned. To make a tag remote, we use git push:
(random_quote) $ git tag v0.1.1 # need to remake since we deleted it above
(random_quote) $ git push origin v0.1.1
Total 0 (delta 0), reused 0 (delta 0)
To [...]/random_quote_remote
* [new tag] v0.1.1 -> v0.1.1
This is very similar to when we ran git push in the last section, but git knows we are only asking to send the new tag to the repository.
To delete a remote tag, we need to let git push know with the --delete flag:
(random_quote) $ git push origin --delete v0.1.1
- [deleted] v0.1.1
Note
At this point, if you've followed along, we've deleted our tag. It would be a good idea to recreate it. Here's a condensed version of the process:
(random_quote) $ git tag v0.1.1
(random_quote) $ git push origin v0.1.1
Total 0 (delta 0), reused 0 (delta 0)
To [...]/random_quote_remote
* [new tag] v0.1.1 -> v0.1.1
Remote vs Local Branches
As with tags, branches exist in local and remote versions. Our branch, so far, only exists in our clone of the repository. This is good, since we were able to fix our bug and merge our changes into master without having to show the code to anyone.
However, when you are collaborating with people, you'll often need to give them access to your code. This is done by making your branch remote.
We use git push to do this, just like we did with tags:
(random_quote) $ git push origin bug-unknown-id
Total 0 (delta 0), reused 0 (delta 0)
To [...]/random_quote_remote
* [new branch] bug-unknown-id -> bug-unknown-id
Tip
It's OK to push to your remote branch frequently. There are a few git actions that are a little more difficult (reverting your changes, for example) once you've pushed, but remember, you are working on a branch, and you will be rebasing later, so there's little risk and you get the benefit of being able to back up your changes to the git remote and show your progress to your collaborators.
Conclusion/What's Next
In this installment, we got a lot more comfortable writing tests and doing stuff with git. At this point, we're ready to do any sort of feature or bug work, and leave a clean commit log when we're done.
In the final part of this series, we'll simulate two developers working on different branches and causing a conflict, which we'll learn how to resolve.